
AIMED-RL - Using reinforcement learning for malware modification
Update 16/12/2021: I added a model card section, as suggested in this paper
Automated, AI guided attacks have become a huge concern and hence research topic in recent years. The idea is indeed frightening: Imagine an AI system which is able to bypass all the layers of security humans have created to secure their systems. It will be able to take control over them and then…
Of course, we are still far away from such a scenario to take place. AI supported automatic malware modifications, however, are already existing. These modifications (also called perturbations) can enable existing malicious software to evade detection by malware classifiers. In order to be able to keep up with the latest possibilities that progress in AI research has created for criminals to refine their attacks, I am advocating the idea that these ways of attacks have to be published in an open source kind of format to be able to defense against them. That is why AIMED-RL, Automatic Intelligent Malware modifications to Evade Detection using Reinforcement Learning has been created. It was the topic of my bachelor’s thesis and is part of the bigger AxMED framework created and supervised by Raphael Labaca-Castro. It focuses on portable executable (PE) Windows binary files (which can be manipulated e.g. by the LIEF library) and on evading static detection. In this post I will describe its purpose and design. And in the end I will also provide an exhaustive tutorial on how-to use it.
Idea and Research Question
Its purpose is quite simple: Deploy a reinforcement learning (RL) environment to create functional malware modifications that are able to evade static detection classifiers. This enables researchers and anti-virus companies to compile large datasets of adversarial malware files modified by models that use the latest techniques from RL research. Ideally, these adversarial files can uncover weaknesses in the detection models and harden them against attacks.
Design
At first, I want to discuss the general RL workflow and thereby shed some light on how AIMED-RL works in the malware environment. It is broken down to its most basic elements, please refer to the paper for more details.
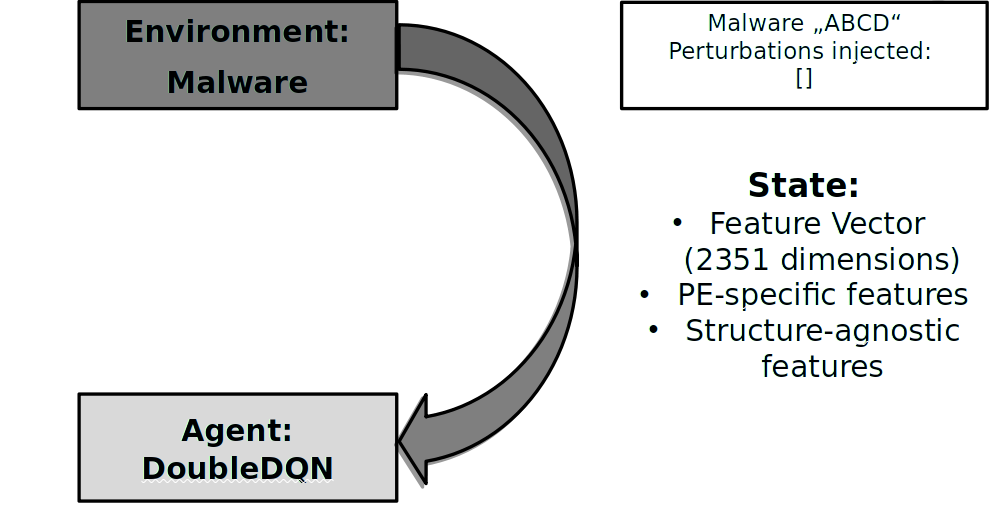 At the beginning, the environment chooses a random malware file from the training set. Using lief library,
a feature vector is calculated that contains both, PE specific features (such as number of sections in the PE file)
and structure-agnostic features (such as byte-level histograms). This feature vector is presented to the agent which
will feeds its neural network with the data.
At the beginning, the environment chooses a random malware file from the training set. Using lief library,
a feature vector is calculated that contains both, PE specific features (such as number of sections in the PE file)
and structure-agnostic features (such as byte-level histograms). This feature vector is presented to the agent which
will feeds its neural network with the data.
 The output from the agent’s neural network consists of a probability distribution. The agent chooses the action with
the highest score and sends its choice to the environment. Here, the malware will get modified with the chosen
modification.
The output from the agent’s neural network consists of a probability distribution. The agent chooses the action with
the highest score and sends its choice to the environment. Here, the malware will get modified with the chosen
modification.
 Finally, the modification is evaluated by presenting the new modified malware file to the classifier (and applying
some other metrices). Thereby, the reward is calculated and sent to the agent which will update its neural network
accordingly. After that, the flow starts again if the malware file is not yet evading the detection classifier.
Finally, the modification is evaluated by presenting the new modified malware file to the classifier (and applying
some other metrices). Thereby, the reward is calculated and sent to the agent which will update its neural network
accordingly. After that, the flow starts again if the malware file is not yet evading the detection classifier.
The environment is based on the gym malware environment from Anderson et al. It uses the OpenAI gym framework and implements the functionalities for the workflow to run. An important aspect of the environment was the design of the reward function. In order to increase the diversity of perturbations used by the agent, we introduced a reward penalty which decreases the agent’s reward if it injects the same perturbation multiple times. This makes also sense on a technical level because most perturbations can only change the PE file once. You can, however, easily switch the reward penalty off and on by setting the reward_penalty flag in the PARAM dictionary.
For the agent, a lot of options are available to choose in the rl.py file. For the paper, we used a combination of a Distributional Double Deep Q-Network with Adam optimizer and Noisy Nets exploration. But of course, any algorithm compatible with chainerrl will work!
Model Card
Model Details:
– Developed by: Raphael Labaca-Castro, Sebastian Franz
– Released: September 2021
– Type: Reinforcement Learning
– Distributional Double Deep Q-Network, Adam optimizer, Noisy Nets exploration
– Paper: Springer
– Source code: GitHub AIMED-RL
– License: MIT/Open Source
– Questions: GitHub AIMED
Intended Use:
– Primary intended uses: Anti-Virus model hardening, security research
– Primary intended users: Scientists, employees of Anti-Virus companies and other security related organizations
– Out-of-scope use cases: Any harmful, offensive or black-hat use. This is neither intended, nor is AIMED-RL a good choice for this “use case”, because it is designed to create a lot of evasive malware, not sophisticating a single one.
Training and Evaluation Data:
– The model was trained on about 4,000 malware files from around 2015-2017. A high variety of malware types was to be found in the dataset (trojans, ransomware, adware, worms etc.).
– The evaluation took place on a holdout dataset of 200 files.
– Unfortunately there are no plans to make the datasets publicly available. This is because the data is potentially dangerous, as functional malware was used for training and evaluation.
Ethical/Social/Political Considerations:
As mentioned above, research in the area of offensive and defensive IT-security is a delicate thing. As stated under “Intended Use” above, any harmful use of our framework is forbidden. Of course, criminals will not care. We still opted to publish our model’s source code, because we want to pull wide attention to possible attacks against cyber-systems. In best case, a defender can be one step ahead of an adversary, which is not a very likely scenario at the moment. This makes any reveal of offensive attack patterns (not to be confused with easily usable exploits) an important contribution to cyber-security, and we want to encourage other researchers to follow this path of Open Science along with us. That being said, we must be very careful when releasing ready-to-use tools that can be abused. For example, a tool that would be able to sophisticate a single, particular malware file would have to be handled with much more care. If you, however, have a different opinion on the topic or even notice a misuse of our research, please do not hesitate to get in touch!
Tutorial - How to use AIMED-RL
Setup
- Create a new virtual (conda) environment and install the requirements from requirements.txt
-
Make sure upx is installed on your system (tested: 3.91, but more recent versions should be fine, too)
- Please ensure that the main function in axmed.py looks like this:
if __name__ == '__main__': scanner = 'GradientBoosting' main('AIMED-RL', scanner) - Configure the PARAM_DICT in the rl.py file with the options you want AIMED-RL to use.
Train/Evaluate
-
Make sure to split your set of malware files in at least two separate sets: A training set (should be located in samples/unzipped for example,
PARAM_DICT["malware_path"]) and an evaluation set (should be located in samples/evaluate_set). The evaluation data must never be included in the training data! -
Call axmed.py with –train and/or –eval to start the AIMED-RL workflow
# Train only: python3 axmed.py --train # Train and eval: python3 axmed.py --train --eval # Only evaluate existing agent python3 axmed.py -dir your-agent-directory --eval
Interpret results
- After a successful run of the AIMED-RL workflow, the db directory will look like this:
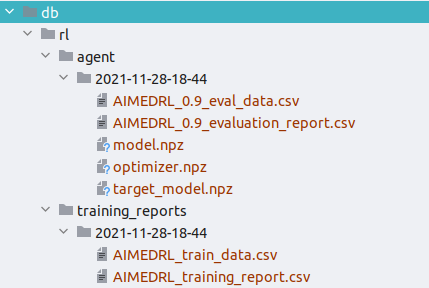
In the …_data.csv files, you can find the data of every single turn that the agent has made. In contrast, the …_report.csv files provide general information about the training or evaluation results and the parameters that have been used for training.
2.For more information about AIMED-RL please refer to the paper. Thanks for your interest in AIMED-RL and AI based security research!
Comments